
The transient world of tech
You happen to come across a new tech, find it fascinating, you try and understand it, learn to use it, even implement it in your workflow. Then a couple seasons pass-by and next thing you know, its obsolete. Some new tech has eclipsed it.
This is the faith of most tools in the world of tech. Sure, you can pledge to keep using something that’s getting obsolete. But, it won’t be easy and it will only get more difficult with time. The community support won’t be strong enough, new tools might not play well with it and the list of issues, shortcomings & todos will keep piling w/o ever being tackled. I am sure this reminds you of a few technologies you came across in a past life, or of legends you’ve heard from your senior colleagues.
We are looking at two such tools today, which we heavily relied on at one of the start-ups I worked at - Apache Mesos and Apache Aurora. They had a short but significant reign; with Virtual Machines being it’s predecessor and Containers it’s successor. Having worked on Virtual Machines in the past, I found Mesos to be fascinating. Its was way faster, more lightweight and efficient. And the way it achieved this was brilliant.
We will be diving deep into these softwares to see how they compare with VMs and Containers. By the end of this, you’ll have a better understanding of how these tools work under the hood and how they achieve their end goal.
So what are Mesos and Aurora?
Apache Mesos is a distributed systems kernel that abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual) to enable effective deployment and operation of your applications on ‘isolated instances’.
These isolated instances function similar to VMs or Containers, but share the host resources. No need for a Guest OS either. They represent individual workloads/tasks (microservices, jobs, etc.) that run on available hardware resources across your cluster. You can even run multiple applications or frameworks (like Hadoop, Spark, Kubernetes, or even custom frameworks) on the same set of machines without them stepping on one another. If you’re aware of Google’s Borg, (predecessor of K8s) some of this might sound similar. Apache Mesos and Google Borg emerged around the same time and aimed to solve similar problems — efficiently scheduling and managing workloads across clusters of servers. But, they had differences in design, usage, and influence. Borg was a proprietary solution that specifically addressed Google’s internal needs for managing vast resources in a reliable, high-availability environment. Mesos was developed as an open-source, general-purpose cluster manager that allowed multiple frameworks to run concurrently on the same cluster.
Apache Aurora is a service scheduler that runs on top of Mesos. It handles resource scheduling, fault tolerance, and task monitoring, making it easier to manage large-scale applications. It also offers features like rolling updates, job quotas, and service health checking, which makes it robust for managing both stateless and stateful workloads.
Together, they provide cluster resource management and isolation, with high-level service scheduling and management features.
Who, Why and When?
Apache Mesos was created by Benjamin Hindman, Andy Konwinski, Matei Zaharia, and a few others at the University of California, Berkeley's AMPLab. The project began around 2009 and was open-sourced in 2010.The primary motivation behind it was to address the growing complexity of managing distributed systems; especially in large-scale data centers. The early 2000s saw a rise in cloud computing, and organizations were running multiple distributed systems for various tasks like web applications, batch processing (e.g., Hadoop), and real-time data streaming (e.g., Spark). Each of these systems needed its own cluster management framework.
Apache Mesos was designed to create a unified cluster management platform that could - run a variety of different distributed applications on a shared pool of resources, dynamically allocate hardware resources (like CPU, memory, storage) to applications as needed and allow applications to co-exist on the same physical or virtual servers, reducing the need to dedicate entire clusters to individual systems.
It aimed to provide a single resource pool that could be efficiently shared by different frameworks, improving resource utilization and simplifying cluster management.
Aurora on the other hand was created sometime later. It was developed at Twitter to address the company's specific needs for running long-running services (like microservices) and cron-like scheduled jobs. Twitter had already adopted Mesos for resource management but needed a higher-level abstraction to manage complex distributed applications and services more effectively. It was open-sourced in 2013.
Apache Aurora provided a service scheduler on top of Mesos for long-running applications (e.g., web services, APIs) and batch jobs (e.g., cron jobs, data processing jobs) and a job scheduling system for running fault-tolerant services, helping Twitter handle service failures and reschedule tasks on available servers.
Aurora allowed developers to specify application requirements and constraints (e.g., CPU, memory, and disk needs) and handled the placement and lifecycle management of tasks across the Mesos cluster.
How does Apache Mesos work?
Master-Agent Architecture:
Apache Mesos follows a master-agent architecture, which is key to how it manages and abstracts resources:
- Mesos Master: The central coordinator that manages the overall state of the cluster, including resources, task scheduling, and interactions with frameworks (applications).
- Mesos Agents (formerly called Slaves): Each physical or virtual server in the cluster runs a Mesos agent, which reports the available resources (CPU, memory, disk, etc.) to the master. The agent is responsible for running tasks assigned to it by the Mesos master. The agents act as intermediaries between the physical/virtual hardware and the tasks, effectively abstracting the hardware details.
Applications do not interact with hardware directly but instead request resources from the Mesos master, which schedules tasks to run on the available agents.
Isolation:
This is the most important and technical aspect of Apache Mesos - ‘How it achieves abstraction and isolation of Hardware resources?’ I’ve talked about this in a dedicated section below.
Resource Offers:
One of the key mechanisms Mesos uses to abstract resources is the resource offer model. Instead of having applications request specific resources upfront, Mesos works the other way around:
- Each Mesos agent periodically reports the available resources (CPU, memory, disk, etc.) on the physical server to the Mesos master.
- The Mesos master then offers these resources to registered frameworks (e.g., Apache Spark, Marathon, Aurora).
- Frameworks decide whether to accept these resources based on their own requirements and then submit tasks to be run on those resources.
This resource offer model decouples applications from the underlying hardware and creates a high-level abstraction where resources are dynamically offered to applications as needed.
Fine-Grained Allocation:
Mesos provides fine-grained control over the allocation of resources, allowing frameworks to specify exact amounts of CPU, memory, disk, and network they require. This allows Mesos to:
- Divide physical resources on each server (CPU cores, RAM, disk, network bandwidth) into smaller, manageable units.
- Isolate resource usage between tasks, ensuring that no task overuses resources or impacts others running on the same agent.
By breaking down server hardware resources into smaller units, Mesos effectively abstracts the physical server into multiple resource slots that can be distributed across different tasks, creating a virtualization-like environment without the overhead of virtual machines.
Framework Abstraction:
Applications running on Mesos use different frameworks (e.g., Apache Aurora, Marathon, or custom frameworks) to manage their workloads. These frameworks request resources from Mesos based on their own scheduling logic. And once resources are allocated, they launch tasks (e.g., microservices, batch jobs) on those allocated resources.
Mesos handles the low-level resource management (like CPU and memory allocation), while the frameworks focus on application-level scheduling. This split creates a further abstraction between the application's logic and the physical resources of the server.
Unified Resource Pool:
By aggregating resources across multiple physical and virtual machines, Mesos creates a unified resource pool for the entire cluster. It treats all resources (across CPU, memory, storage, and network) as if they come from a single, large server.
Applications running on Mesos are not concerned with where the physical resources reside (which server, data center, etc.). The Mesos master abstracts the underlying servers, allowing the applications to interact only with the available resources, without needing to know about the specific hardware details. This unified resource pool makes it easy to run distributed applications, big data frameworks, and microservices at scale without having to manage the underlying hardware manually.
Scalability and Fault Tolerance:
Mesos design allows it to scale across thousands of machines. The Mesos master and agents work together to dynamically adjust resource allocation as new tasks come in. Mesos is capable of handling failures by reassigning tasks to available resources on healthy agents.
By abstracting hardware resources at scale, Mesos ensures that no single machine becomes a point of failure and that resources are continuously available, even in the event of failures.
How does Mesos achieve abstraction & isolation of hardware resources?
Apache Mesos achieves abstraction of server hardware resources by acting as a distributed resource manager or a cluster manager. It abstracts the underlying physical or virtual server infrastructure into a single resource, isolating them with Cgroups and namespaces. (Linux kernel features) All this allows applications to efficiently share and utilize the available resources (CPU, memory, disk, network, etc.) across a distributed cluster.
Cgroups and namespaces:
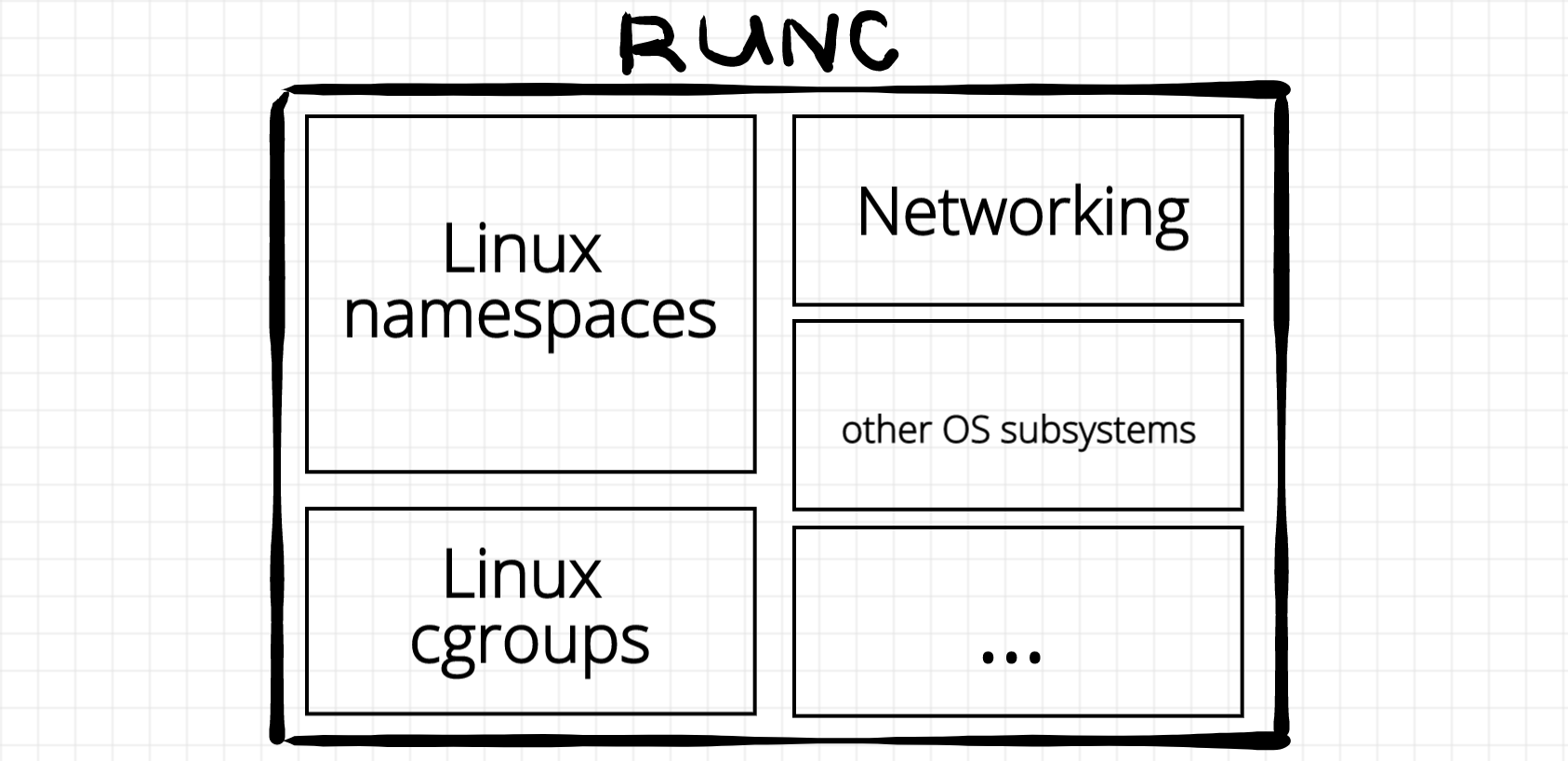
Control Groups (cgroups) is a Linux kernel feature that limits, monitors, and manages the resources (CPU, memory, disk I/O, network bandwidth, etc.) that a group of processes can use. It allows system administrators or orchestration tools to control the amount of system resources allocated to processes or groups of processes. Without cgroups, processes can potentially consume excessive resources, leading to resource contention or even starvation of other processes.
Key Features of Cgroups:
- Resource Limitation: You can set upper limits on the amount of CPU, memory, disk I/O, and other resources that a group of processes can consume.
- Resource Monitoring: Cgroups can track the resource usage of processes, providing real-time information about how much CPU or memory a task is consuming.
- Resource Prioritization: By assigning priorities to different cgroups, you can control how resources are shared among processes, making sure that critical processes get more resources than less critical ones.
- Freezing/Throttling: Cgroups can pause or limit resource consumption temporarily if needed, preventing a process from monopolizing resources.
Examples:
- CPU Limitation: Cgroups can ensure that one task (process) uses only 40% of the CPU, while another uses the remaining 60%. This prevents a poorly-behaved or resource-hungry task from hogging all the CPU resources.
- Memory Isolation: Cgroups can cap the amount of memory a process or group of processes can use. If a process exceeds this limit, it will be killed or its allocation will be constrained, protecting other tasks from being affected by out-of-memory errors.
- Disk I/O: Cgroups can limit how many disk read/write operations a task can perform. This prevents tasks from monopolizing the disk, which could slow down the performance of other processes.
- Freezing/Throttling: Cgroups can pause or limit resource consumption temporarily if needed, preventing a process from monopolizing resources.
Namespaces are a Linux kernel feature that provides process-level isolation by wrapping global system resources (such as file systems, network interfaces, process IDs, and user IDs) into independent instances. This makes it appear as if each group of processes has its own private view of these resources, even though they are all running on the same underlying operating system. Processes running in one namespace are unaware of the resources in other namespaces, ensuring that they cannot interfere with each other.
There are several types of namespaces, each isolating a different system resource. Some of these are - PID Namespace, Mount (MNT) Namespace, Network (NET) Namespace, Time Namespace, IPC Namespace and User Namespace.
Examples:
- PID Namespace: Processes in different PID namespaces have their own process ID space. This means that two processes in different namespaces can have the same PID but will never see each other. This isolation is essential for containers, where each container behaves as if it has its own private process space.
- Network Namespace: Each network namespace can have its own network interfaces and routing tables. This allows different applications or containers to have completely independent networking stacks, preventing them from interfering with each other’s network traffic.
- Mount Namespace: Processes in a mount namespace can have their own view of the file system, with their own mounted directories and devices. This allows applications to be isolated from each other’s file systems, so they cannot see or modify each other’s files.
How does Apache Aurora work?
Apache Aurora provides a framework for deploying and managing long-running services, cron jobs, and batch jobs across a Mesos cluster. Here’s how Aurora achieves this within the Mesos ecosystem:

Job Definition and Configuration:
In Aurora, users define jobs using a configuration file written in a DSL (Domain-Specific Language) like Python or JSON. These jobs specify the resources requirements (CPU, memory, disk) and other parameters (e.g., health checks, replication, etc.).
Example Job Configuration (Aurora Job File):
job = Job(
name = "billing_service",
environment = "prod",
role = "billingteam",
task = Service(
name = "billing_server",
cpu = 0.25, # 0.25 CPU per instance
ram = 2048, # 2GB of RAM per instance
disk = 512, # 512MB of disk space
instances = 8, # We want 8 instances running
process = Process(
name = "billing_server_process",
cmdline = “/usr/local/bin/start-billing-service", # Command to start the service
max_failures = 3 # Retry upto 3 times before reporting failure
),
health_check = HealthCheck(
url = "http://localhost:8080/health",
interval_secs = 10,
timeout_secs = 5
)
)
)
Service Scheduling and Deployment:
Aurora takes these job definitions and works with Mesos to deploy the jobs across available nodes in the cluster. Aurora ensures that:
- Jobs are deployed on the right nodes based on the resource requirements and constraints defined in the configuration. Example: X CPU, Y RAM and Z Disk space.
- Jobs are replicated, ensuring that a defined number of instances (tasks) are running at all times. Example: 20 instances of microservice X.
Monitoring and Health Checks:
Aurora continuously monitors the state of each task and performs health checks. If a task crashes or fails its health check, Aurora automatically restarts it on another available node.
Resilience and Fault Tolerance:
If a node fails, Aurora re-schedules tasks on other available nodes, ensuring that services remain operational even in the event of hardware or software failures.
Cron Jobs and Batch Processing:
Aurora supports running scheduled tasks (similar to cron jobs) and can also be used for batch processing. These jobs are scheduled based on the timing and frequency defined in the job's configuration file
Key Components of Aurora:
- Scheduler: The brain of Aurora, responsible for managing the lifecycle of all tasks and interacting with the Mesos master to request resources.
- Executor: The component that runs tasks on Mesos agents, ensuring that tasks are executed as defined by the job configuration.
- Thermos: A lightweight executor framework used by Aurora to monitor and restart tasks. Thermos is responsible for task-level retries and management.
- Tasks: The individual units of work defined in Aurora jobs. A task represents an instance of an application or service running on a Mesos agent.
Virtual Machines V/S Mesos Instances V/S Containers
Now that we know what Apache Mesos is and how it works with Apache Aurora to offers a powerful platform for managing large-scale distributed systems, lets look at how it differs from (and in some ways is similar to) - what was before (i.e. VMs) and what came after. (i.e. Containers)
Compared to Virtual Machines (VMs):
The primary difference between Mesos instances and Virtual Machines (VMs) lies in the way they manage and abstract resources on a physical server. Here's a detailed comparison:
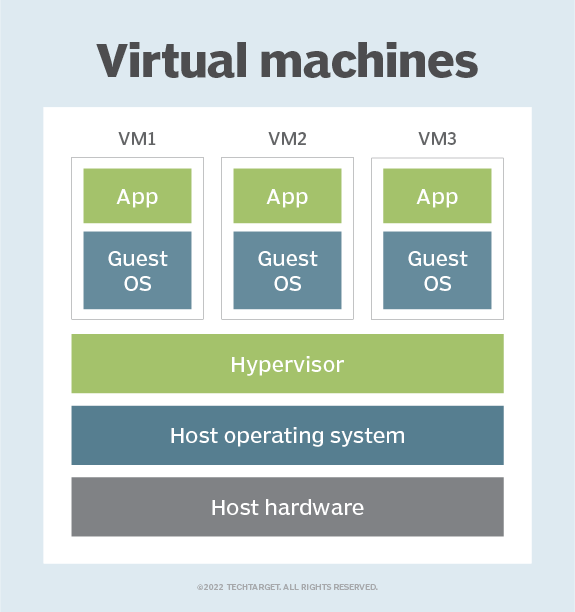
- Full OS virtualization: In a VM-based environment, each virtual machine runs a complete guest OS (including its own kernel) on top of the host OS. The hypervisor isolates the VMs and allocates resources, but there is more overhead because each VM runs a full OS instance.
In contrast, Mesos instances do not run a separate OS. Instead, they share the host OS kernel with other instances, reducing overhead. - Isolation: VMs provide stronger isolation compared to Mesos instances, as they run entirely separate guest OS. Mesos provides application-level isolation using cgroups and namespaces, but instances still share the host's kernel.
- Less Granular: Virtual machines typically have static resource allocation, meaning once resources (CPU, RAM) are allocated, they are locked to the VM, limiting flexibility in scaling at finer levels compared to Mesos instances.
- Slower Boot Times: VMs take longer to start because they must boot a full OS, whereas Mesos instances are simply processes started within the existing OS, resulting in much faster startup times.
- Strong Isolation: VMs provide full isolation at the OS level. Each VM is completely isolated from others, making it more secure in terms of kernel vulnerabilities. A security breach in one VM typically does not affect other VMs.
- Multiple OSes: If there’s a need to run multiple operating systems (e.g., Linux, Windows) on the same physical host, VMs are preferred since each VM can run a completely different OS.
- Multi-Tenancy: VMs are ideal when strict isolation is required, such as in multi-tenant environments, where different customers or applications should not interact at any level, including OS.
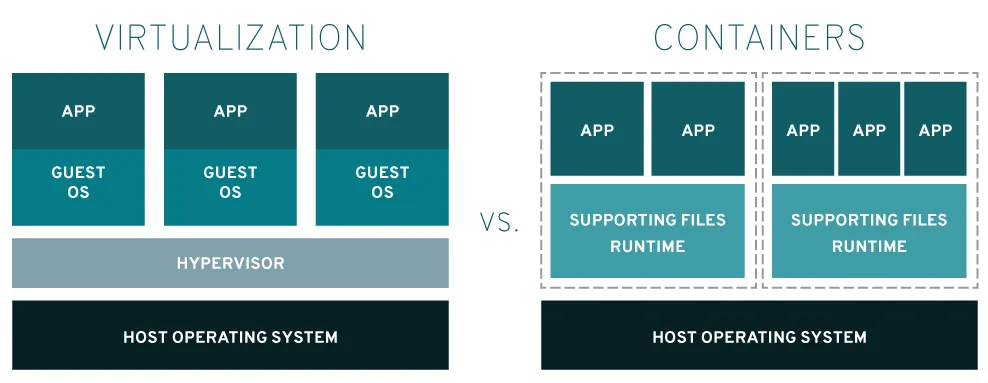
Compared to Containers:
Mesos instances and Containers are somewhat related and share some similarities. However, there are key distinctions between the two in terms of how they handle isolation, resource management, and their underlying technologies. Let’s look at what these similarities, differences and overlaps are:
- Isolation Mechanisms: Containers do not require an entire OS; instead, they share the host OS kernel but have isolated user spaces, making them more lightweight compared to VMs. Containers (like Mesos instances) also rely heavily on Linux Cgroups and namespaces for isolation, offering a self-contained environment with isolated process IDs (PID), networking, filesystems, and user environments. But this isolation is stricter than Mesos instances.
- Resource Management: Containers also rely on cgroups for resource management, but the resource allocation is usually managed by the container runtime (such as Docker) or an orchestrator like Kubernetes. Containers allow you to limit the CPU, memory, and other resources for each container instance. However, resource management may not be as sophisticated or fine-grained as Mesos' multi-resource handling unless integrated with a higher-level orchestrator.
- Deployment and Orchestration: Mesos instances are scheduled and managed by Mesos and, optionally, Aurora or other frameworks like Marathon.
Containers are typically deployed and managed by a container orchestration platform like Kubernetes or Docker Swarm, which is responsible for scheduling, scaling, and managing containers.Orchestrators handle the lifecycle of containers, ensuring availability, load balancing, scaling, and recovery in case of failure. - Statefulness and Persistence: Mesos instances can handle both stateless and stateful workloads. Mesos frameworks (e.g., Aurora, Marathon) have built-in support for persistent volumes, allowing stateful services to run with reliable storage. Plus, Mesos has the ability to handle multiple types of workloads (microservices, batch jobs, big data processing, etc.) making it highly flexible.
Containers are typically designed to be ephemeral and stateless. Any persistent storage needs to be mounted from external sources, such as network-attached storage, cloud-based storage (e.g., EBS, NFS), or container-specific storage solutions (e.g., Kubernetes Persistent Volumes). While containers can also be used for stateful services, managing persistence requires extra effort and orchestration. - Performance Overhead: Containers are lightweight, but they do introduce a small amount of overhead compared to running directly on the host. This is due to the added layer of isolation provided by the container runtime. Containerized applications may have slightly lower performance than non-containerized applications running on Mesos because of the overhead involved in managing the container's environment.
- Mesos Can Use Containers: While Mesos instances are not exactly containers, Mesos can use containers (e.g., Docker, Mesos native containerizer) to run instances, like you run any other job/task on Mesos. In this case, the instances are containers that offer process and resource isolation while sharing the host OS kernel.